
When I first starting working with computers everything was in ASCII ( American Standard Code for Information Interchange )
However today working with networking protocols and network programming you will come across a variety of data and character encoding schemes.
In this tutorial we will look at basic encoding schemes used on computers and in the second part of the tutorial we look at how data is sent over a network.
Characters, Integers, Floats etc
When storing and transmitting data you will need to represent Following Data Types:
- Characters and numbers e.g A and 1
- Integers Signed and Unsigned Long (32 bits) and Short (16 bits)
- Floating Point Single and Double
- Boolean i.e True and False
So how does a computer store the letter A or the number 1?
How the computer store a number like 60101 ? or 62.0101?
How do you transmit the letter A etc to another machine across a network?
Computers and Character Encoding
To store text as binary data, you must specify an encoding for that text.
Computers systems can use a variety of character encoding schemes.
As long as the data stays on the computer it is really unimportant how it is encoded.
However to transfer data between systems a standard encoding scheme needs to be adopted.
In 1968 the ASCII (American Standard Code for Information Interchange) was adopted as a standard for encoding text for data exchange.
ASCII
ASCII is an American standard as designed to encode English characters and punctuation as used on typewriters and teletypes of that era (1960s).
ASCII uses 8 bits although only 7 bits are actually used.
Because ASCII was developed at the time Teletype devices were in operation it also contains control codes designed to control the teletype device.
The Table below show a summary of the code allocation.
|
ASCII Table – Code Summary |
|
| Decimal Value | Use |
| 0-31 | Control codes |
| 32-127 | Printable characters |
| 128-255 | Unused |
ASCII Extensions
Because ASCII cannot encode characters like the pound sign £ or common characters found in German and other European languages various extensions were developed.
These extensions kept the ASCII character set and used the unused portion of the address space and control codes for additional characters.
The most common ones being windows 1252 and Latin-1 (ISO-8859).
Windows 1252 and 7 bit ASCII were the most widely used encoding schemes until 2008 when UTF-8 Became the most common.
ISO-8859-1,ISO-8859-15, Latin-1
ISO-8859 is An 8 bit character encoding that extends the 7 bit ASCII encoding scheme and is used to encode most European Languages. See wiki for details.
ISO-8859-1 also know as Latin-1 is the most widely used as it can be used for most of the common European languages e.g German, Italian, Spanish, French etc.
It is very similar to the windows-1252 encoding scheme but not identical see- Comparing Characters in Windows-1252, ISO-8859-1, ISO-8859-15
Unicode
Because of the need to encode foreign language symbols and other graphic characters the Unicode character set and encoding schemes were developed.
The most common encoding schemes are :
- UTF-8
- UTF-16
- UTF-32
UTF-8 is the most commonly used encoding scheme used on today’s computer systems and computer networks.
It is a variable width encoding scheme and was designed to be fully backwards compatible with ASCII. It uses 1 to 4 bytes. – wiki
Character Sets and Encoding Schemes
The distinction between the two isn’t always clear and the terms tend to be used interchangeable.
A character set is a list of characters whereas an encoding scheme is how they are represented in binary.
This is best seen with Unicode.
The encoding schemes UTF-8, UTF-16 and UTF-32 use the Unicode character set but encode the characters differently.
ASCII is a character set and encoding scheme.
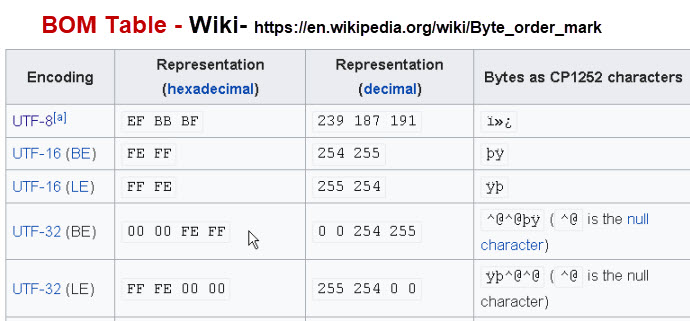
Byte Order Mark (BOM)
The byte order mark (BOM) is a Unicode character, U+FEFF that appears as a magic number at the start of a text stream and can signal several things to a program consuming the text: –Wiki
- The byte order, or endianness, of the text stream;
- The fact that the text stream’s encoding is Unicode, to a high level of confidence;
- Which Unicode encoding the text stream is encoded as.
The BOM is different for UTF-8, UTF-16 and UTF-32 encoded text
The following table, taken from Wiki, shows this.
BOM and Text Editors
Generally most editors handle the BOM correctly and it isn’t displayed.
Microsoft software like Notepad add a BOM when saving data as UTF-8 and cannot interpret text without a BOM unless it is pure ASCII.
BOM Example
The screenshot below shows a simple text file containing the text TEST encoded as UTF-8 in notepad:
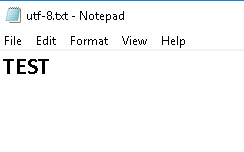
You should notice that the BOM characters are not visible.
Below is the output of a simple python program that displays the contents of a file containing the characters TEST (4 characters) stored as ASCII, UTF-8, UTF-16-BE and UTF-16-LE

Reference– The byte-order mark (BOM) in HTML
Common Questions and Answers
Q-How do I know what character encoding a file uses?
A- Normally you don’t but some text editors like notepad++ will display the encoding. If you receive a file that is encoded using a different encoding than expected then you may get an error when trying to read it.
Q- My file is in ASCII but It decodes ok using UTF-8 decoder. Why is that?
A- Because UTF-8 is backwards compatible with ASCII.
Integers and Floats -Big and Little Endian
Note: Because UTF-16 and UTF-32 use 2 byte or 4 byte integers the following applies to text encoding using them
The number of bytes allocated to an Integer or float is system dependent.
Tutorials point covers this for the C programming language and I will use that for illustration
If we take a short integer as 2 bytes and a long integer as 4 bytes.
Because they use several bytes then several questions arise:
- Which byte represents the most significant part of the number?
- When stored in memory which byte is stored first
- When sent on a network which byte is sent first.
Endianness refers to the sequential order in which bytes are arranged into larger numerical values when stored in memory or when transmitted over digital links.
Endianness is of interest in computer science because two conflicting and incompatible formats are in common use: words may be represented in big-endian or little-endian format, depending on whether bits or bytes or other components are ordered from the big end (most significant bit) or the little end (least significant bit.
In big-endian format, whenever addressing memory or sending/storing words bytewise, the most significant byte—the byte containing the most significant bit—is stored first (has the lowest address) or sent first, then the following bytes are stored or sent in decreasing significance order, with the least significant byte—the one containing the least significant bit—stored last (having the highest address) or sent last.
The illustration below using python to show the integer 16 represented as 4 bytes using big and little endian byte order.
Network Byte Order and System Byte Order
Network Byte Order refers to how bytes are arranged when sending data over a network. ( TCP/IP is generally Big Endian ).
This means most significant byte is sent first.
System or Host Byte Order refers to how bytes are arranged when stored in memory on the host system.
Windows OS is Little Endian.
Ref- Bit and Byte Ordering video
[googlead]
Related Tutorials
ASCII uses 8 bits although only 7 bits are actually used. And then Ext. ASCII was introduced to use all 256 values of the 8 bits which are equivalent to UTF-8.
Ref: https://www.ascii-code.com/
This show all the values which include: DEC, OCT, HEX, BIN, Symbol, HTML Number, HTML Name, and Description of the value, ie, NULL=0, line feed=10, carrage return=13.
I hope you continue the article about this