
![]() HTTP stands for hypertext transfer protocol and is used to transfer data across the Web.
HTTP stands for hypertext transfer protocol and is used to transfer data across the Web.
It is a critical protocol for web developers to understand and because of it widespread use it is also used in transferring data and commands in IOT applications.
The first version of the protocol had only one method, namely GET, which would request a page from a server.
The response from the server was always an HTML page.- Wiki
To give you an idea of how simple the HTTP protocol started out take a look at the Original specification which was only 1 page.
There have been several versions of HTTP starting with the original 0.9 version.
The current version is 1.1 and was last revised in 2014. See Wiki for more details.
How It Works
Like most of the Internet protocols http it is a command and response text based protocol using a client server communications model.
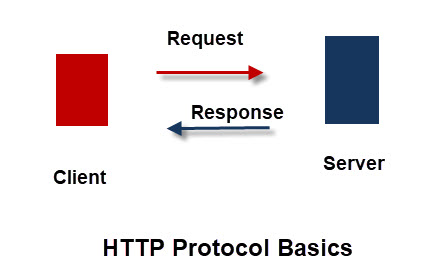
The client makes a request and the server responds.
The HTTP protocol is also a stateless protocol meaning that the server isn’t required to store session information, and each request is independent of the other.- See this wiki
This means:
- All requests originate at the client ( your browser)
- The server responds to a request.
- The requests(commands) and responses are in readable text.
- The requests are independent of each other and the server doesn’t need to track the requests.
Request and Response Structure
Request and response message structures are the same and shown below:

A request consists of:
A command or request + optional headers + optional body content.
A response consists of:
A status code + optional headers + optional body content.
A simple CRLF (carriage return and Line feed) combination is used to delimit the parts, and a single blank line (CRLF ) indicates end of the headers.
If the request or response contains a message body then this is indicated in the header.
The presence of a message body in a request is signalled by a Content-Length or Transfer-Encoding header field. Request message framing is independent of method semantics, even if the method does not define any use for a message body. – RFC 7230 section 3.3.
Note: the message body is not followed by a CRLF See RFC 7230 section 3.5
HTTP Requests
We saw the general request response format earlier now we will cover the request message in more detail.
The start line is mandatory and is structured as follows:
Method + Resource Path + protocol version
Example if we try to access the web page testpage.htm on www.testsite5.com
The the start line of the request would be
GET /test.htm HTTP/1.1
Where
- GET is the method
- /testpage.htm is the relative path to the resource.
- HTTP/1.1 is the protocol version we are using
Notes:
- A relative path doesn’t include the domain name.
- The web browser uses the URL that we enter to create the relative URI of the resource.
Note: URL (uniform resource Locator) is used for web pages. It is an example of a URI (uniform resource indicator).
The actual http request is not shown by the browser, and is only visible using special tools like http header live (Firefox).
HTTP vs URL
Most people are familiar with entering a url into a web browser. Usually looking like this.

The url can also includes the port which is normally hidden by the browser, but you can manually include it as shown below:

This tells the web browser the address of the resource to locate and the protocol to use to retrieve that resource (http).
http is the transfer protocol that transfer the resource (web page,image,video etc) from the server to the client.
HTTP Responses and Response Codes
Each request has a response. The Response consists of a
- STATUS code And Description
- 1 or more optional headers
- Optional Body message can be many lines including binary data
Response Status codes are split into 5 groups each group has a meaning and a three digit code.
- 1xx – Informational
- 2xx – Successful
- 3xx -Multiple Choice
- 4xx– Client Error
- 5xx -Server Error
For example a successful page request will return a 200 response code and an unsuccessful a 400 response code.
You can find a complete list and their meaning here
Request Response Example
We are going to examine he requests and response when we access a simple web page (testpage.htm)
Here is what I enter in the browser address bar:

and this is the response that the browser displays:
and here is a screen shot of the http request-response that happens behind the scenes.

Notice the request headers are automatically inserted by the browser, and so are the response headers are inserted by the web server.
There is no body content in the request. The body content in the reply is a web page, and is shown in the browser, and not by the live headers tool.
Request Types
So far we haven’t mentioned request types, but we have seen the GET request type in our examples.
The GET request type or method is used for requesting a resource from a web server.
GET is most commonly used request type and was the only request type in the Original HTTP specification.
Request Types, Methods or Verbs
The HTTP protocol now support 8 request types, also called methods or verbs in the documentation,they are:
- GET – Requesting resource from server
- POST – submitting a resource to a server (e.g. file uploads)
- PUT -As POST but replaces a resource
- DELETE-Delete a resource from a server
- HEAD – As GET but only return headers and not content
- OPTIONS -Get the options for the resource
- PATCH -Apply modifications to a resource
- TRACE -Performs message loop-back
On the Internet today the GET (getting web pages) and POST (submitting web forms)methods are the ones most commonly used.
The Other methods are used when working with Web and IOT APIs specifically put,delete and head.
There is a good basic overview on w3 schools, and the Microsoft MDN site covers them in more detail.
Related Tutorials and Resources
Love your website and articles
Thanks, it was very helpful.
exactly.
What headers are compulsory to add when sending a request? I know HOST: and CONNECTION: has to be added, question is what if I don’t add USER-AGENT etc?
Hi
I believe Host is the only required header.If you don’t supply the headers required by the application then you may not get the desired response.
Thanks for the information. What does CRLF stand for? And what does it mean?
Looking forward to Part 2 HTTP headers.
Carriage return and Line Feed.
Why is HTTP version number presented in both a request line and a statue line
It is in the request and response and indicates the version used by the browser and the version supported by the server.